这个一开始的暂时的小的reward 就叫 Sparse Reward
如何让agent在Sparse Reward 中拥有更好的学习表现?
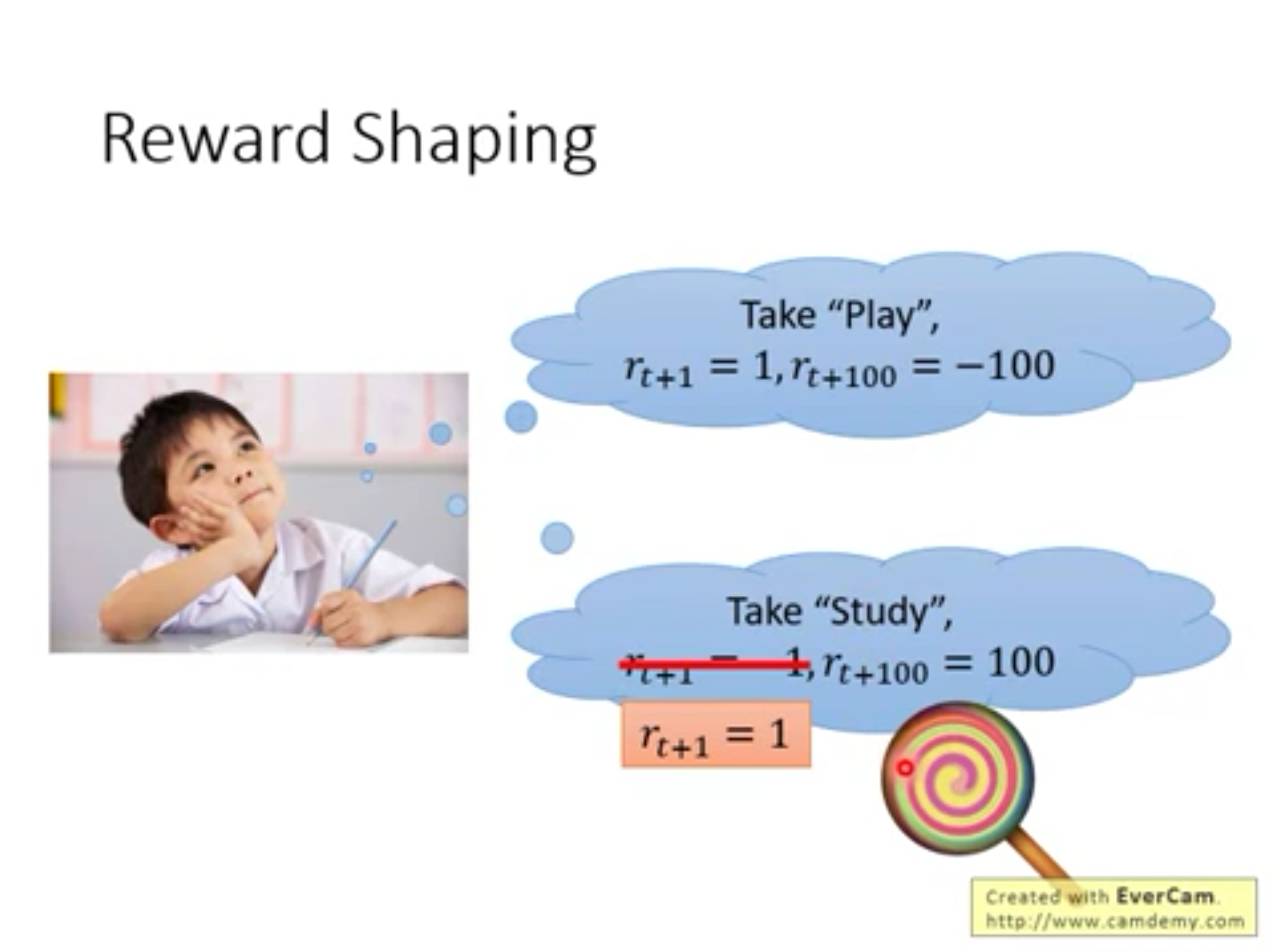
1.“写完作业就给糖吃”
把关键的一些动作强制地定义为正的reward,这样agent就不会反感这一学习行为,从而一步步走到最大的reward
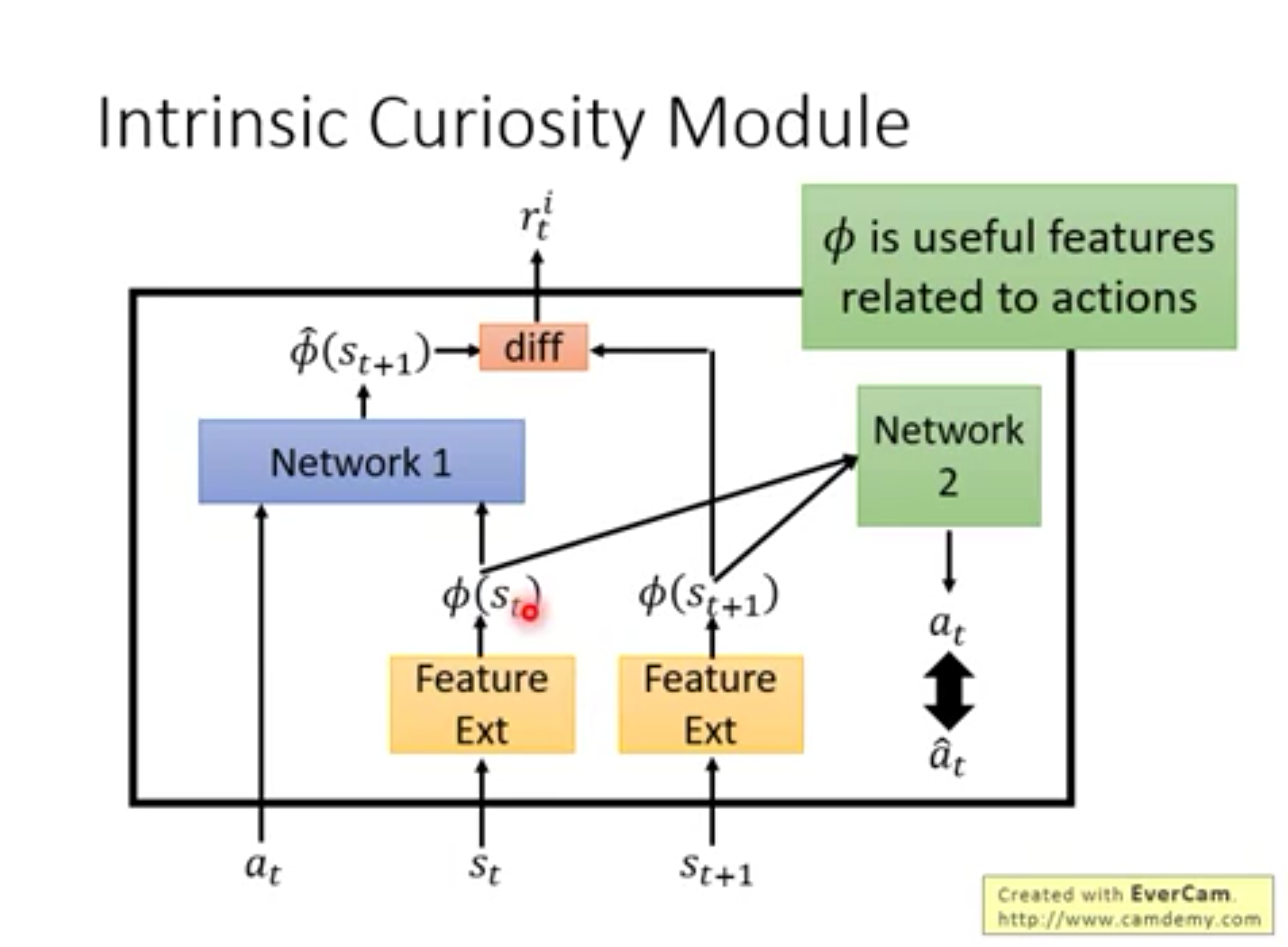
2.“兴趣是最好的老师 ” Curiosity Module
尽管是一些风吹草动,很难让agent得到一些有用的反馈。这时让agent自己预测这个动作将来的reward,这样也能达到最终的效果。让agent预测做一个动作的未来的reward,从而使agent有兴趣的学习。
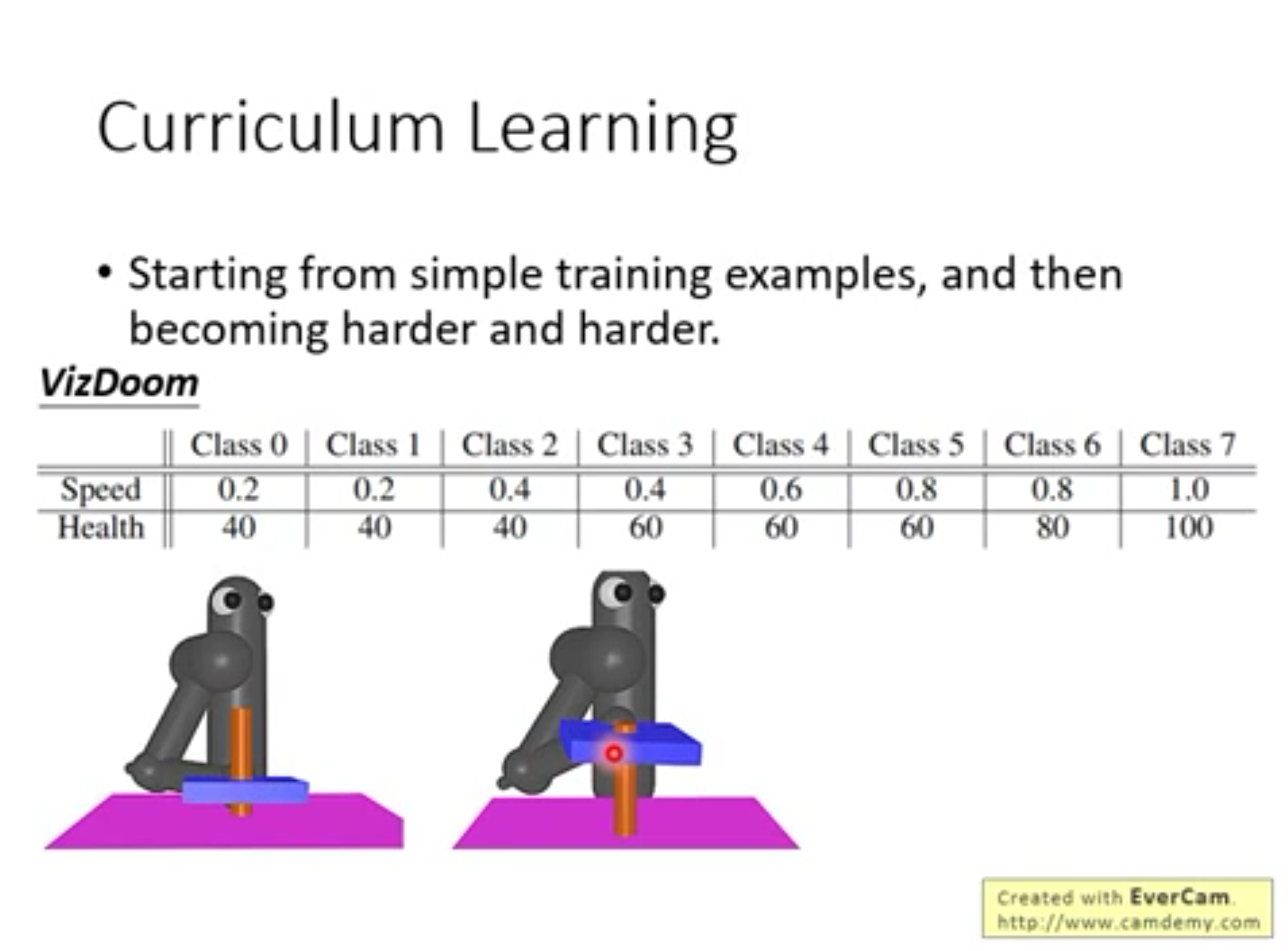
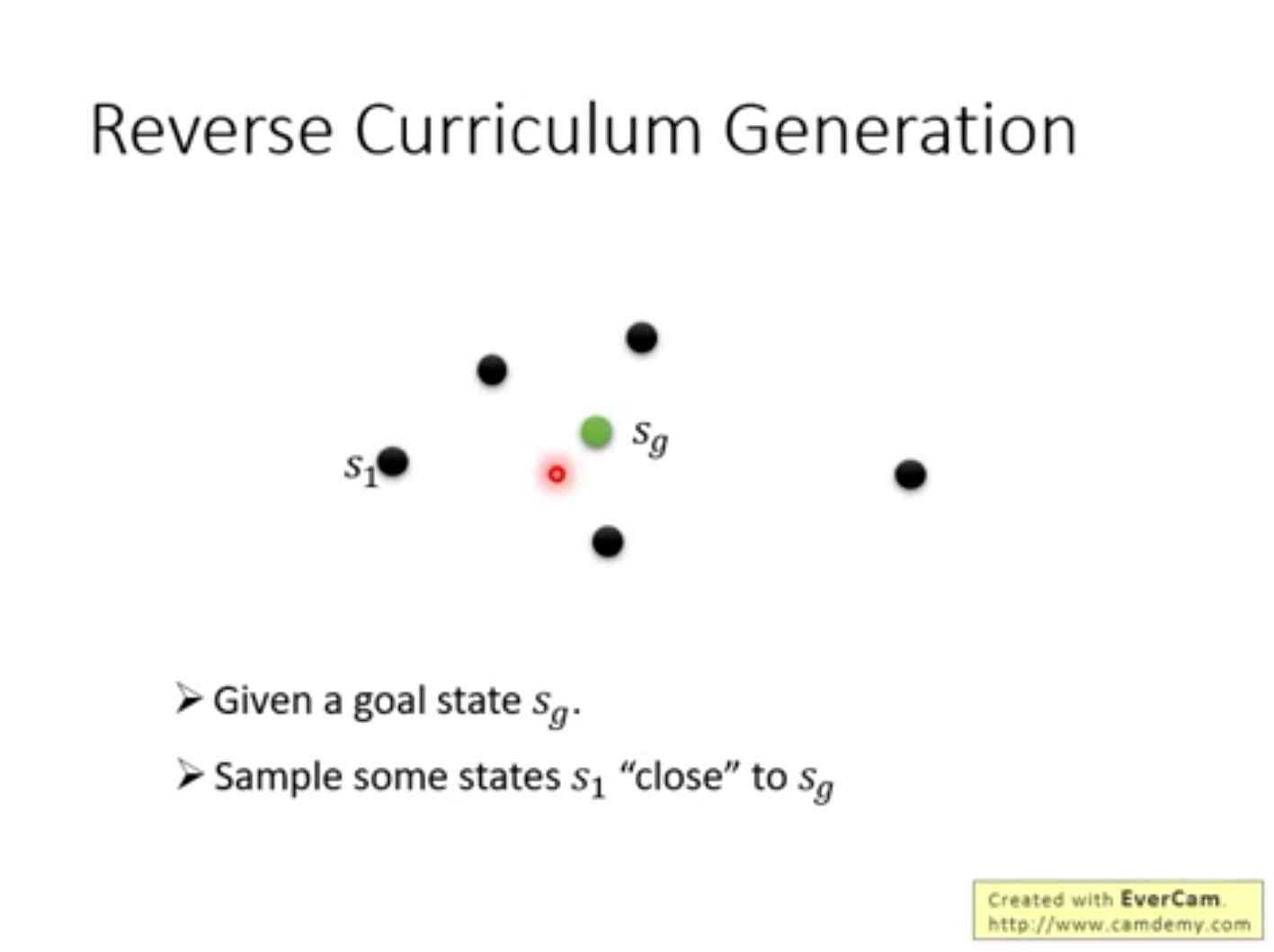
3.“制定学习计划” Curriculum Learning
人来设定agent的学习顺序,使agent以从易到难的顺序学习
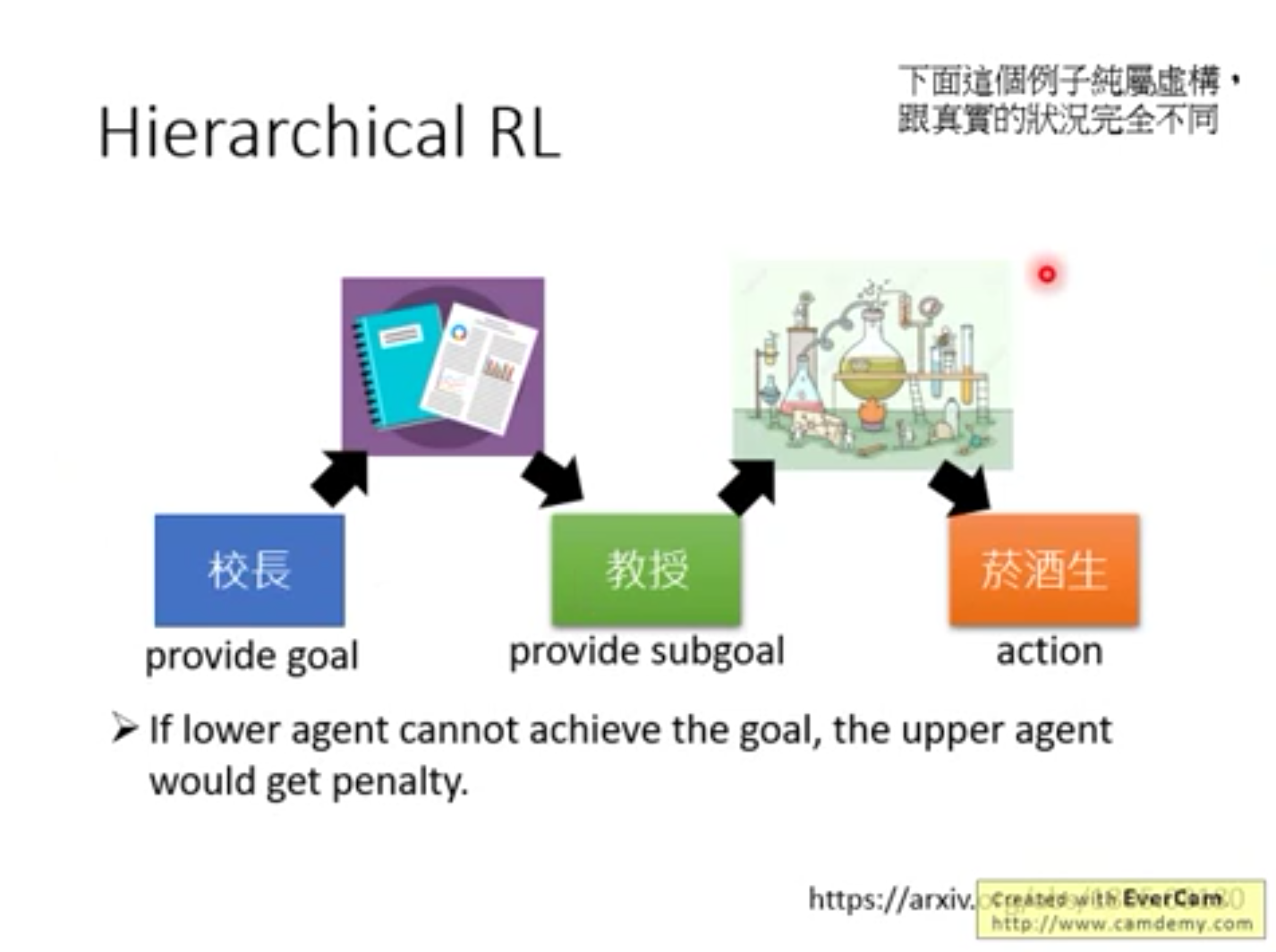
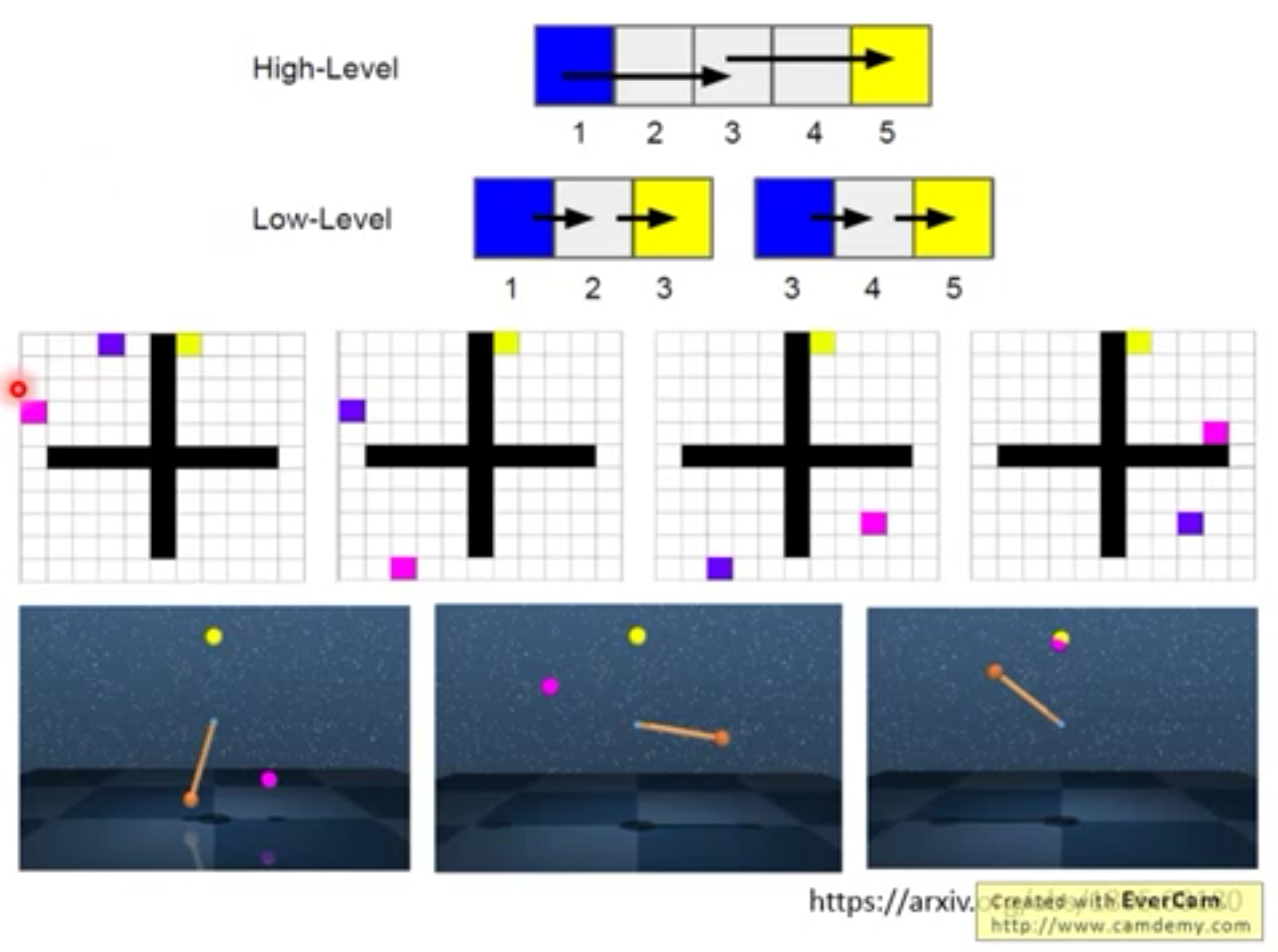
4.阶层式强化学习 Hierarchical RL
由上层agent提出愿景,由最下层agent来执行动作