西瓜书习题3.4 (交叉验证法):
选择两个UCI数据集,比较10折交叉验证法和留一法所估计出的对率回归的错误率.
1.数据集长啥样?
于是就下载了一组UCI数据集,它长这样:

至于这些数据是啥意思、UCI又是啥,咱也不知道咱也不敢问qwq~,只知道有748行、5列,在咱眼里它就是一个 (748 * 5)的矩阵。第5列数据是0和1,那它肯定是labels,属于二分类问题。
2.啥是十折交叉验证法?啥是留一法?
k折交叉验证法:
我们将数据集随机分成k份,使用其中 k-1 份进行训练而将另外1份用作测试。该过程可以重复 k 次,每次使用的测试数据不同。
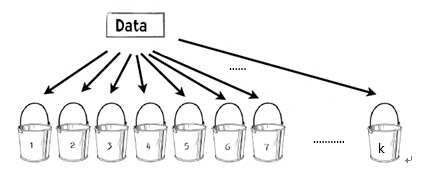
(1)每一次迭代中留存其中一个桶。第一次迭代中留存桶1,第二次留存桶2,其余依此类推。
(2)用其他 k-1 个桶的信息训练分类器(第一次迭代中利用从桶2到桶 k 的信息训练分类器)。
(3)最终返回这 k 次测试结果的accuracy的均值
十折交叉验证法就是 k=10 的情况
留一法则是 k=总样本数 的情况,即每次迭代从总样本取一条数据做测试集,剩余的全做训练集
3.以上一顿分析猛如虎,是时候该撸码实现啦 qwq
1 | import numpy as np |
结果是:
1 | LeaveOneOut's Accuracy: 0.7831325301204819 |
可以发现留一法准确率高十折交叉验证法将近4个百分点,其实差别不是很大,但使用留一法的运算时间却十分漫长
其原因是十折交叉验证法只需训练10个模型,而留一法则需要训练跟样本数量一样多的模型,而本次样本数量为748,速度慢一大截
可见,在数据集比较大时,留一法并不适用。(例如100万个样本,则需要训练100万个模型,编程几分钟,训练好几天?)